FAQs on: General
The Weekly Schedule Page presents all you need to know in chronological order (for each week) while the other pages have some of the same content organized by topic.
The Weekly Schedule Page is the one page you need to refer weekly. Although there is a lot of content in the Admin Info page and the Textbook page -- which you are welcome to read in those respective pages -- the same content is also cross-embedded in the corresponding weekly schedule pages. Such cross-embedded extracts usually appear in expandable panels and can be identified by the symbol in the panel title.
In CS2103/T, A+ is not given simply based on the final score. To get an A+ you should,
- score enough to be close to the higher end of the
Agrade band. - be considered technically competent by peers and tutor (based on peer evaluations and tutor observations).
- be considered helpful by peers (based on peer evaluations and tutor observations).
- In particular, you are encouraged to be active on the forum and give your inputs to ongoing discussions so that other students can benefit from your relatively higher expertise that makes you deserve an A+.
- Whenever you can, go out of your way to review pull requests created by other team members.

Sometimes, small things matter in big ways. e.g., all other things being equal, a job may be offered to the candidate who has the neater looking CV although both have the same qualifications. This may be unfair, but that's how the world works. Students forget this harsh reality when they are in the protected environment of the school and tend to get sloppy with their work habits. That is why we reward all positive behavior, even small ones (e.g., following precise submission instructions, arriving on time etc.).
But unlike the real world, we are forgiving. That is why you can still earn full marks for participation even if you miss a few things here and there.

Slides are not meant to be documents to print and study for exams (the textbook is the resource more suitable for exam prep). Their purpose is to support the briefing delivery and keep you engaged during the briefing. That's why our slides are less detailed and more visual.
Defining your own unique project is more fun.
But, wider scope → more diverse projects → harder for us to go deep into your project. The collective know-how we (i.e., students and the teaching team) have built up about SE issues related to the project become shallow and stretched too thinly. It also affects fairness of grading.

That is why a strictly-defined project is more suitable for a first course in SE that focuses on nuts-and-bolts of SE. After learning those fundamentals, in higher level project courses you can focus more on the creative side of software projects without being dragged down by nuts-and-bolts SE issues (because you already know how to deal with them). However, we would like to allow some room for creativity too. That is why we let you build products that are slight variations of a given theme.
Also note: The freedom to do 'anything' is not a necessary condition for creativity. Do not mistake being different for being creative. In fact, the more constrained you are, the more you need creativity to stand out.
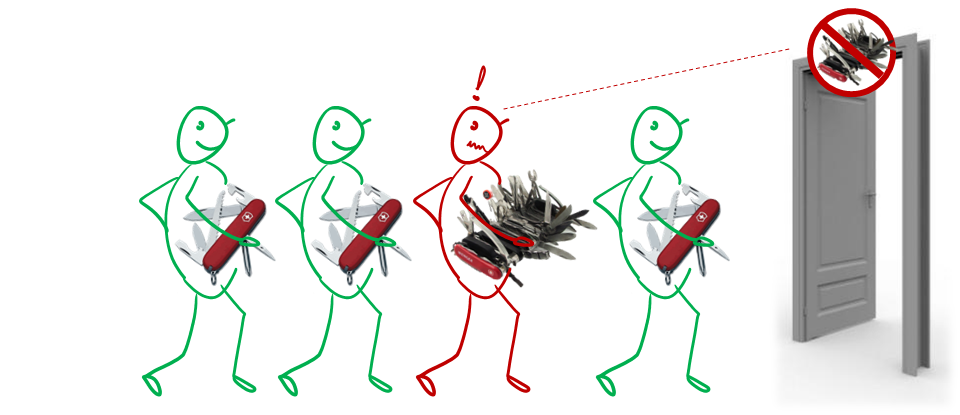
We have chosen a basic set of tools after considering ease of learning, availability, typical-ness, popularity, migration path to other tools, etc. There are many reasons for limiting your choices:
Pedagogical reasons:
- Sometimes 'good enough', not necessarily the best, tools are a better fit for beginners: Most bleeding edge, most specialized, or most sophisticated tools are not suitable for a beginner course. After mastering our toolset, you will find it easy to upgrade to such high-end tools by yourself. We do expect you to eventually (after this course) migrate to better tools and, having learned more than one tool, to attain a more general understanding about a family of tools.
- We want you to learn to thrive under given conditions: As a professional Software Engineer, you must learn to be productive in any given tool environment, rather than insist on using your preferred tools. It is usually in small companies doing less important work that you get to chose your own toolset. Bigger companies working on mature products often impose some choices on developers, such as the project management tool, code repository, IDE, language etc. For example, Google used SVN as their revision control software until very recently, long after SVN fell out of popularity among developers. Sometimes this is due to cost reasons (tool licensing cost), and sometimes due to legacy reasons (because the tool is already entrenched in their codebase). While programming in school is often a solo sport, programming in the industry is a team sport. As we are training you to become professional software engineers, it is important to get over the psychological hurdle of needing to satisfy individual preferences and get used to making the best of a given environment.
Practical reasons:
- Some of the topics are tightly coupled to tools. Allowing more tools means tutors need to learn more tools, which increases their workload.
- We provide learning resources for tools. e.g. 'Git guides'. Allowing more tools means we need to produce more resources.
- When all students use the same tool, the collective expertise of the tool is more, increasing the opportunities for you to learn from each others.
Meanwhile, feel free to share with peers your experience of using other tools.
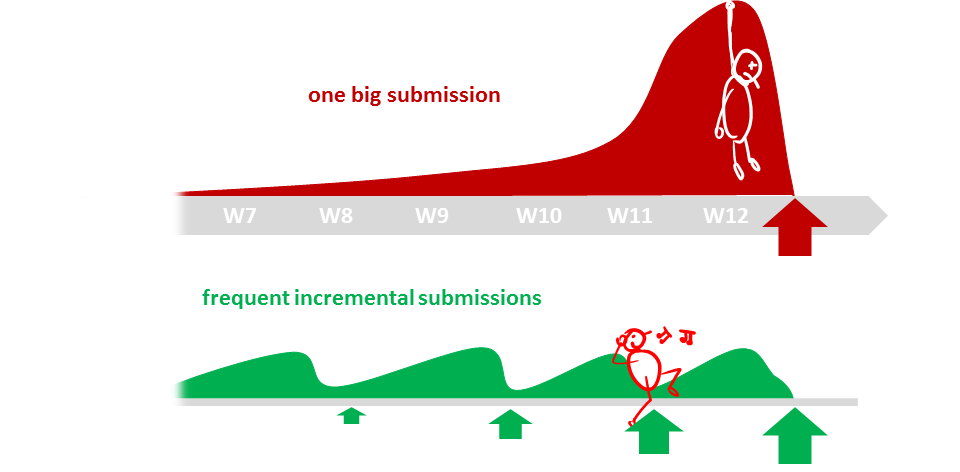
The high number of submissions is not meant to increase workload but to spread it across the semester. Learning theory and applying them should be done in parallel to maximize the learning effect. That can happen only if we spread theory and 'application of theory' (i.e., project work) evenly across the semester.
In addition, spreading the work across the semester aligns with the technique that we apply in this course to increase your retention of concepts learned.
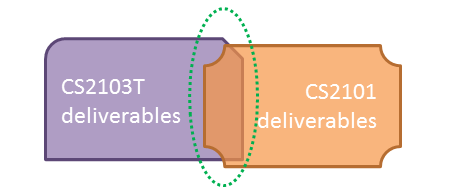
CS2103T communication requirements are limited to a very narrow scope (i.e., communicate about the product to users and developers). CS2101 aims to teach you technical communication in a much wider context. While you may be able to reuse some of the stuff across the two courses, submission requirements are not intended to be exactly the same.
In most quizzes, answers will be released within a day after the quiz deadline.
On a related note, if you are not confident about the answer you've selected for a question, you are welcome to discuss it in the forum, even if the submission deadline is not over yet (but one question per thread please).
FAQs on: iP
Adding a git tag in the iP is a self-declaration that you think you are done with the iP increment. We take your word for it. We don't check the code to see if you have actually done the said increment. Therefore, it is just a mechanism for you to self-declare progress and for us to monitor those progress declarations.
Go ahead and fix it in a subsequent commit. There is no need to update the previous commit or move the corresponding tag to the new commit. As we do not test your code at every tag, earlier bugs will not affect your grade as long as they are fixed eventually. Similarly, feel free to improve the code of previous increments later.
It's fine. Be more careful in the future. Your iP marks will not be affected for missing an occasional deliverable such as this one.
If you still want to make that branch-___ item green in the iP dashboard, you can simply create a branch with the required branch name, do some commits in it, and merge it to master. The dashboard will accept it as long as it has the right name and merged to the master branch.
FAQs on: Tutorials
TLDR: In this course, tutor's main job is to deliver tutorials. Hence, tutors can answer questions related to (and arising from) the tutorial delivery. But they are not allowed to answer admin questions. They are not allowed to help with technical issues.
- Good I did not understand your explanation of that question. Why did you say "a b c"?
Reason: This question is a follow-up from a tutorial discussion. - Good This is how I understood coupling. Is that correct?
Reason: This question shows you have put in some effort to learn the topic and seeking further clarification from the tutor. - Bad What is coupling? | What is SLAP?
Reason: These are concept covered in the textbook and other resources provided. - Bad How will this be graded? | What happens if this submission is late?
Reason: Tutors are not allowed to answer admin questions. - Bad My program crashes with this error; what to do?
Reason: Tutors are not allowed to help with technical issues (post your issue in the forum instead).
Our tutorial participation bar has enough of a buffer to allow an occasional absence (irrespective of the reason for absence). While we are not able to make special arrangements for absences due to reasons not accepted as valid by NUS (e.g., due to family event, interview, travel delays, overslept etc.), such absences are unlikely to affect your participation marks unless frequent.
- You are welcome to keep your tutor informed of such absences as a courtesy, but it is not a requirement.
- If you miss a tutorial, do try to catch up as best as you can e.g., by watching the tutorial recording.
In the past, many students have requested to increase the tutorial duration because a mere hour is barely enough to get through all the tutorial tasks. Increasing the tutorial time is not possible due to lack of venues and tutors. Instead, let's try to make the best of the one hour available by coming well-prepared and starting on time. Note that the better prepared you are, the higher the chance of completing all activities allocated to a tutorial within time.
FAQs on: tP
- It is an opportunity to exercise your product design skills because optimizing the product to a very specific target user requires good product design skills.
- It minimizes the overlap between features of different teams which can cause plagiarism issues. Furthermore, higher the number of other teams having the same features, less impressive your work becomes especially if others have done a better job of implementing that feature.
The size of the target market is not a grading criterion. You can make it as narrow as you want. Even a single user target market is fine as long as you can define that single user in a way others can understand (reason: project evaluators need to evaluate the project from the point of view of the target users).
In that case, at a later stage, you can add more user stories until there is enough for a meaningful work distribution. But at this point focus on selecting the smallest sub-set of must_have user stories only.
Yes, even if you don't plan to change them.
Reasons:
- To show that you have examined, understood, and agree with, the current behavior of those features.
- AB3 does not have a feature spec covering those features (and the UG does not cover all details of a feature).
But you may copy-paste parts of the UG onto your feature spec if that helps. Also, you may omit existing AB3 feature that are not must-have, and hence, need not be included in the MVP.
It is OK (i.e., no penalty) if you overshoot the deadline in initial iterations. Adjust subsequent iterations so that you can meet the deadline consistently (which is an important learning outcome of the tP) by the time you reach the end of the tP.
Yes (an example), although having too many non-coding tasks in the issue tracker can make it cluttered.
GitHub Issues does not have a direct way of doing this. However, you can use a task list in the issue description to indicate sub-tasks and corresponding issues/PRs -- (an example)
This is discouraged in the tP, as it makes task allocations (and accountability) harder to track.
Instead, shared tasks can be split into separate issues. For example, instead of creating an issue Update teams page with own info and assigning it to all team members (in which case, this issue can't be closed until all members do their part), you can create issues such as Update teams page with John's info that can be assigned to individual members.
A: In the tP (in which our grading scripts track issues assigned to each member), it is better to create separate issues so that each person's work can be tracked separately. For example, suppose everyone is expected to update the User Guide (UG). You can create separate issues based on which part of the UG will be updated by which person e.g., List-related UG updates (assigned to John), Delete-related UG updates (assigned to Alice), and so on.
This is encouraged, while not a strict rule. Creating an issue indicates 'a task to be done', while a PR is 'a task being done'. These are not the same, and there can be a significant time gap between the two.
Furthermore, posting an issue in advance allows the team to,
- anticipate a PR is coming
- discuss more about the task (in the issue thread) e.g., alternatives, priority
- indicate who will be doing the task (by adding an assignee), when it should be done (by adding it to a milestone)
While this multi-step-command approach (i.e., giving the user a series of prompts to enter various data elements required to perform an action) has its benefits (e.g., no need to memorize the command format), a deeper look reveals why the one-shot-command approach is better.
Before delving any further, note how leading CLI-centric software such as Git and Linux don't use the multi-step approach either. Why?
The multi-step approach basically results in a 'text-based GUI simulation' that is harder to use than an actual GUI (obviously), whereas a well-designed CLI in an expert's hands can perform tasks faster than an equivalent GUI (which is what we are going for). A person good at typing and remembers the command can type a command faster than a user going through a type-read-type-read sequence required by the multi-step-command. Now imagine user made a mistake in the response to an earlier prompt -- correcting that would take a lot more work.
That being said, multi-step-commands can complement the one-shot-command approach in specific cases e.g.,
- as a crutch for new users to learn the command format
- to be used for rarely-used tasks or tasks requiring multiple steps (e.g., importing data from a file)
Given your product is supposed to be an address book variant, it is fine to keep using 'AddressBook' in class/package names.
But remember to change any user-visible mention of AddressBook at places where the user expects to see the name of your product, and will be confused by seeing a different name instead.
Caution: Mass renaming can disrupt authorship tracking. So, it is best to do any mass renaming at earlier stages of the tP (but you are still allowed to rename them even at later stages).
The DG is primarily meant to help current/future developers. In general, the DG is expected to provide minimal yet sufficient guidance for developers, serving them in the following ways:
- It act as a starting point for developers, before they can dive into the code itself e.g., by providing an architecture-level overview of the system
- It provides a roadmap to developers e.g., pointing out where important information can be found in the code
- It complements the code, providing info/perspectives not specified in the code (e.g., rationale for high-level design choices, details of dev ops)
or not easy to grasp from the code (e.g., architecture level view, visual models).
Therefore, decide based on how the inclusion/exclusion affects that target audience (you belong to the target audience too!) in achieving the above objectives.
You are welcome to add new content/diagrams, but it is not a strict requirement. Consider costs (e.g., the effort required to add and maintain new content) vs benefits (how much the new content helps future developers) and decide accordingly. However, everyone is expected to contribute to the DG, which means you should divide the DG-update work among team members.
- We expect all students to have some experience working with DG UML diagrams, to verify that you are able to handle similar diagramming tools in the future.
- If your code changes don't require updates to existing UML diagrams or adding new diagrams,
- you can document a 'proposed' feature or a design change that you might do in a future iteration, which gives you an opportunity to add some UML diagrams.
- Also take a closer look at the features you added -- not needing changes to UML might (but not always) be a sign that the features you added didn't go deep enough. In the context of the tP, it is better to add one big feature, rather than add many small insignificant features.
Yes, you may use any other tool too (e.g., PowerPoint). But wait; if you do, note the following:
- Choose a diagramming tool that has some 'source' format that can be version-controlled using git and updated incrementally (reason: because diagrams need to evolve with the code that is already being version controlled using git). For example, if you use PowerPoint to draw diagrams, also commit the source PowerPoint files so that they can be reused when updating diagrams later.
- Use the same diagramming tool for the whole project, except in cases for which there is a strong need to use a different tool due to a shortcoming in the primary diagramming tool. Do not use a mix of different tools simply based on personal preferences.
So far, PlantUML seems to be the best fit for the above requirements.
Not a good idea. Given below are three reasons each of which can be reported by evaluators as 'bugs' in your diagrams, costing you marks:
- They often don't follow the standard UML notation (e.g., they add extra icons).
- They tend to include every little detail whereas we want to limit UML diagrams to important details only, to improve readability.
- Diagrams reverse-engineered by an IDE might not represent the actual design as some design concepts cannot be deterministically identified from the code e.g., differentiating between multiplicities
0..1vs1, composition vs aggregation.
Yes, you may remove them, but you are welcome to keep them too (they can be useful if a team member is unable to find any other UML diagram to update).
If you keep them in the DG, update them to match the current version of the product. Otherwise, outdated content can be reported as DG bugs.
Not surprisingly, a common question tutors receive is "can you look at our project and tell us if we have done enough to get full marks?". Here's the answer to that question:
The tP effort is graded primarily based on peer judgements (tutor judgements are used too). That means you will be judging the effort of another team later, which also means you should be able to make a similar judgement for your own project now. While we understand effort estimating is hard for software projects, it is an essential SE skill, and we must practice it when we can.
The expected minimum bar to get full marks for effort is given here.
If you surpass the above bars (in your own estimation), you should be in a good position to receive full marks for the effort. But keep in mind that there are many other components in the tP grading, not just the effort.
Yes, the submitted MVP Feature Specification is not binding (its purpose was to get you to think about feature details early -- we will not be looking at it again). You may change features as needed along the way. Just ensure your changes do not violate tp constraints.
No need to resubmit the Feature Spec either. However, if you change the product name, target user, or the value proposition, (which is allowed too) please email the updated values to cs2103@comp.nus.edu.sg.
Not necessarily. It depends on the effort required, which in turn depends on what the code does. It is quite possible for 100 LoC that implements feature X to take more effort than 300 LoC that implements feature Y (i.e., it depends on the feature). So, we measure the effort, not LoC (LoC figure given is just a rough estimate of the equivalent effort).
There is no such guarantee, for two reasons:
- Your implementation effort is graded based on how much functionality your team produced (based on peer-testers' and tutors' estimates) and how much of that work was contributed by you (based on team members' estimates). For example, simply copy-pasting 400+ LoC with only minor modifications is unlikely to meet this bar as it is less than an effort equivalent to writing a typical 300-400 LoC (or half of a typical iP effort).
- Implementation marks are based on both effort and quality, the latter being the primary driver (more info here). So, meeting the effort bar doesn't guarantee full marks for implementation.
In very early iterations, try to keep the existing tests (and CI) working. It is OK not to add new tests.
In general, there are several options you can choose from:
- Update/add tests every time you change functional code. This is what normally happens in stable production systems. For example, most OSS projects will not accept a PR that has failing tests or not enough new tests to cover the new functional code.
- Disable failing tests temporarily until the code is stable. This is suitable when the functional code is in a highly volatile state (e.g., you are still experimenting with the implementation). The benefit is that you avoid the cost of writing tests for functional code that might change again soon after. Some costs: (a) harder to detect regressions during the period tests are disabled (b) testing debt piles up which could distort your estimate of real progress (c) forgetting to enable the tests in time.
This is still a viable option during some stages of a tP e.g., during the early part of an iteration, or while a PR is still in 'draft' state (i.e., for getting early feedback from the team). - Decide certain tests are not worth the effort to maintain, and delete them permanently. Result: Less test code to maintain but higher risk of undetected regressions.
In some cases the code edited by the PR is not covered by existing tests, which means Codecov will report it as not adhering to the current coverage targets.
First, find out which area of the code is causing the coverage drop. You can use Codecov or code coverage features of the IDE to do so.
Then you can do the following:
- Ignore those warnings, and merge the PR (a member with admin permissions can merge a CI-failing PR). Suitable for cases such as,
- the coverage drop is in code that is not normally covered by automated tests and/or 'not worth the effort to' test automatically (e.g., GUI).
- you deem that automated testing of that part of the code can be done at a later time (i.e., not a priority at the current time).
- Alternatively, update tests until the coverage is raised back to sufficient level.
Note that Codecov is there to help you manage code coverage -- it is not graded. You may lower the test coverage targets set for Codecov as well.
For reference,
In general, it is better for a PR to update code, tests, and documentation together.
In early iterations, it is fine not to update documentation, to keep things simple. We can start updating docs in a later iteration, when the code is more stable.
Not necessarily. Choose based on importance.
In any project, there are always things that can be done 'if there was more time'. If fixing a certain bug has low impact on users, and fixing it is not as important as the work done (or intend to do in the current iteration), you can justify not fixing it with the reason 'not in scope' of the current iteration.
Similarly, a missing feature enhancement can be justified as 'not in scope' if implementing that could have taken resources away from other important project tasks.
Bugs and possible enhancements 'not in scope' will not be penalized.
Automated GUI testing is hard, especially in Desktop apps, especially in CI (because the environment that CI runs doesn't have a display device to show the GUI).
A few years ago, we used AB4 as the starting point of the tP.
- The main difference between AB4 and AB3? AB4 has automated GUI testing. It used the TestFX tool to do so, and ran the test in 'headless' mode in CI (i.e., simulate a display device without an actual display device).
- The main reason we changed tP to start with AB3 code was that some students found it too hard to maintain those GUI tests.
While we don't require you to automate GUI testing in your tP (i.e., it is fine to do only manual GUI testing), you are welcome to give it a try too, especially if you like a technical challenge.
- Even if you get it working in only some OS'es only, and only in local environment, it is still a useful way to test the GUI quickly.
- It is possible to run tests selectively, which means you can still run them in environments they work and skip them in other environments.
Feel free to reuse/refer AB4 code too. If you manage to make some headway in this direction, you are encouraged to share it with others via the forum.
Here are some reasons:
- We want you to take at least two passes at documenting the project so that you can learn how to evolve the documentation along with the code (which requires additional considerations, when compared to documenting the project only once).
- It is better to get used to the documentation tool chain early, to avoid unexpected problems near the final submission deadline.
- It allows receiving early self/peer/instructor feedback.
In terms of effort distribution, it's up to the team to tell us who did how much. Same goes for assigning bugs. So, it's fine for someone to take over a feature if the team is able to estimate the effort of each member, and they have a consensus on who will be responsible for bugs in that feature.
For code authorship, only one person can claim authorship of a line, and that person will be graded for the code quality of that line. By default, that will be the last person who edited it (as per Git data) but you can override that behavior using @@author tags.
FAQs on: tP PE
Yes, you may. Given that the dev team did not get to see this addition info when they triaged the bug, the weight such additional info add to your case is lower than if you had that info in the initial bug report. Nevertheless, it can still help your cause, especially if the dev team should have thought about that info on their own, even if they were missing in the initial bug report.
FAQs on: tP Troubleshooting
It is possible that the master branch has received new commits after your PR passed CI the last time. So, if GitHub indicates that your PR is not up-to-date with the latest master branch, synchronize your PR branch with the master branch (which will run the CI again) before merging it.
First, check which OS it is failing in. Some behaviors can be OS-dependent. For example, file paths are case-insensitive in Windows but not in Unix/Mac.
Second, note that PR CI does a temporary merge of master branch to the PR branch before running tests, to verify if the checks will pass after you merge this PR. So, if the master branch has progressed after you started your PR branch, those new commits can affect the CI result. The remedy is to pull the master branch to your repo, merge it to your PR branch, and run tests again (which should fail as well, but you can now find the reason for the failure and fix it).
As each product is tested by 4-5 testers, after all PE bugs have been finalized, we know how 'buggy' each product is. We then use that information for calculating your PE-related marks. So, the marks are calibrated to match the bugginess of the product you tested.
No. Given the PE has only a short time, we don't expect you to find all bugs in the product. To get full marks, you only need to report a certain percentage of the bugs (e.g., half), or a certain quantity of bugs (the quantity also factors in the nature of the bug e.g., severity), whichever is lower.
Penalty for bugs is applied based on bug density, not bug count. Here's an example:
nbugs found in Ann's feature; it is a big feature consisting of a lot of code → marks for dev testing: 4nbugs found in Jim's feature; it is a small feature with a small amount of code → marks for dev testing: 1
Although both had the same number of bugs, as Ann's work has a lower bug density than Jim's, she earns more marks for the dev testing aspect.
Yes, you may. Given that the dev team did not get to see this addition info when they triaged the bug, the weight such additional info add to your case is lower than if you had that info in the initial bug report. Nevertheless, it can still help your cause, especially if the dev team should have thought about that info on their own, even if they were missing in the initial bug report.
FAQs on: Exam
You are welcome to try past exam papers available in the library and post answers in the forum to discuss with others. The teaching team will contribute to those discussions as well, and ensure you reach a reasonable answer.
Caution: The scope of the course and the exam format evolve over time and some past questions may not be exactly in sync with the current semester.